Healthcare providers are drowning in paperwork, with a recent study revealing physicians spend an average of 1.77 hours daily completing documentation outside of office hours. The average doctor spends 16 minutes per patient just dealing with electronic health records (time taken from actual patient care). And healthcare burns through $1 trillion annually on administrative tasks, with much of that waste tracing back to documentation systems that simply don't work.
Some healthcare systems are turning to automation to help eliminate these problems. But while your smartphone's voice assistant nails everyday conversation with 95% accuracy, when you drop that technology into a hospital, performance crashes to 70-80%.
It's not the beeping machines or hallway chatter causing the problem, either. It's the specialized language that doctors speak every day. When a cardiologist says "myocardial infarction with ST-elevation," most speech-to-text systems spit out something that looks like autocorrect gone wrong.
Better microphones won't fix this. Quieter rooms won't either. What healthcare needs is Voice AI that actually understands medical language with precision.
New advances in speech language models are finally making that possible.
Why traditional speech recognition models struggle in healthcare
Traditional speech-to-text models fail with medical terminology because they're trained on general datasets where medical terms appear rarely. When an AI voice agent encounters "pneumothorax" once for every million instances of common words like "awesome," the statistical imbalance causes consistent recognition failures.
This statistical rarity creates a cascade of problems. Medical terms don't just sound different—they follow entirely different linguistic rules. Pharmaceutical names blend Latin roots with modern chemistry. Anatomical terms stretch across multiple syllables with precise pronunciation requirements. And medical acronyms are context minefields where "MI" could mean myocardial infarction, mitral insufficiency, or medical interpreter (depending on the specialty).
Clinical environments make everything worse. Emergency departments layer urgent conversations over equipment alarms. Operating rooms have multiple speakers wearing masks. ICU consultations happen over ventilator noise. Standard automatic speech recognition expects clean audio with clear speaker separation, not the controlled chaos of actual healthcare, and research confirms this vulnerability, showing a 7.4% error rate in notes generated by speech recognition software before human review.
The industry has tried patches:
- Custom vocabulary training demands specialty-specific datasets and constant updates as medical knowledge evolves.
- Post-processing correction systems layer rule-based fixes on top of broken transcriptions, often creating new errors.
- Specialized medical models cost six figures, lock you into narrow use cases, and have generalization and contextual understanding issues.
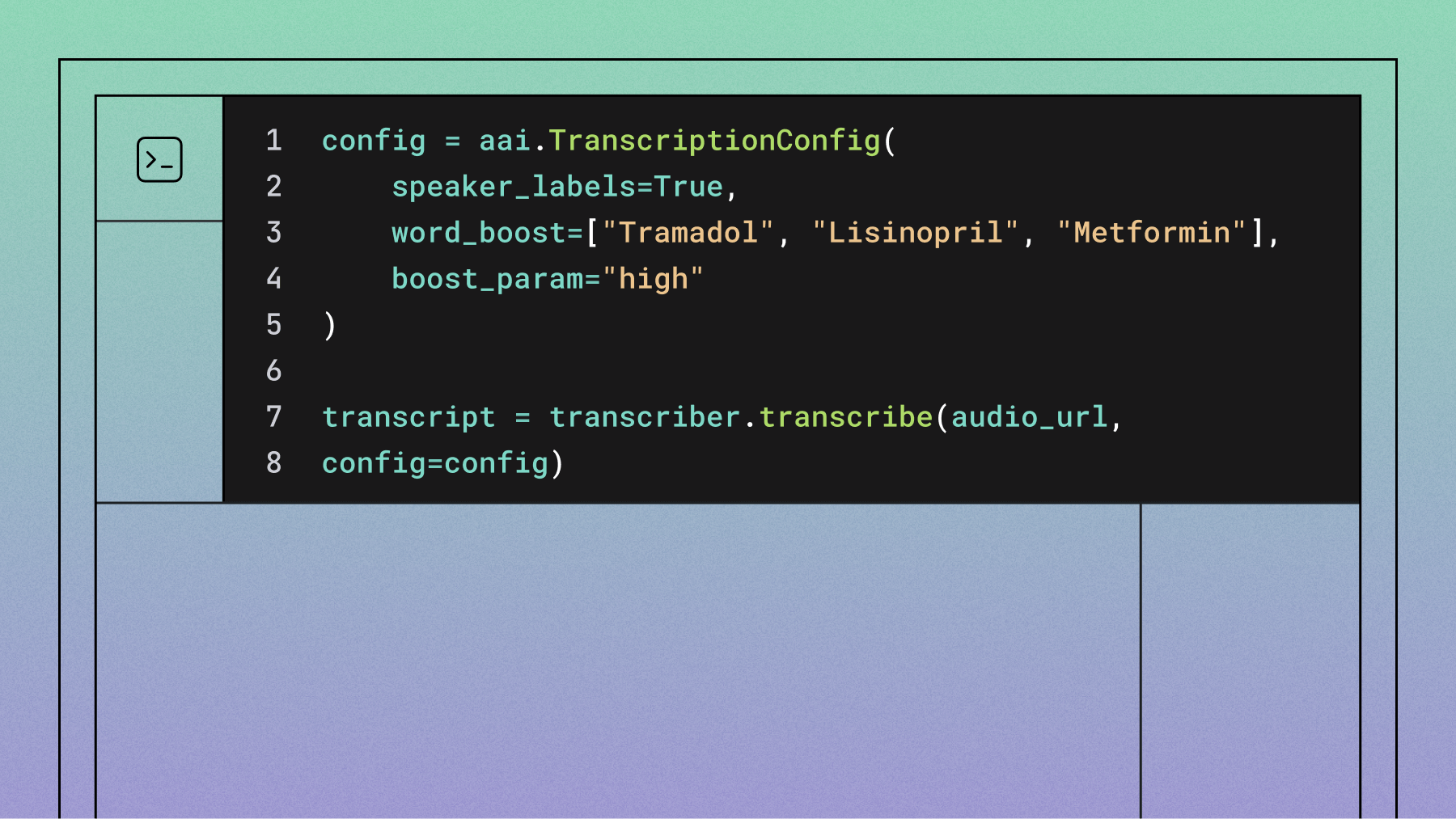
- Word boosting techniques seem like they can improve specific term recognition but in reality, using massively long lists of words contradicts the initial purpose of boosting specific words (i.e. 98% of the words would be distractors).
These aren't solutions. They're expensive workarounds for fundamentally mismatched technology.
See medical transcription accuracy
Try speech recognition on your own clinical audio in our Playground. See it capture complex terminology and acronyms with medical precision.
Try Playground
Slam-1: a revolutionary approach to medical speech recognition
Slam-1 introduces a new approach to medical speech recognition. Instead of training another speech-to-text model on more medical data, it builds something fundamentally different: a Speech Language Model that combines LLM reasoning functionality with specialized audio processing.
This isn't just better pattern matching. It's genuine understanding.
Most speech recognition systems hear audio patterns and map them to text sequences. Slam-1 hears the audio, processes the semantic meaning, then generates appropriate text based on context. When it encounters "bilateral pneumothorax," it doesn't just recognize the sound pattern—it understands that this refers to collapsed lungs on both sides and maintains that medical precision throughout the transcript.
The technical breakthrough comes from Slam-1's multi-modal architecture:
- An acoustic tower first processes raw audio to extract key features and then translates them into a format the language model can understand.
- These audio features are fed into a powerful, pre-trained LLM that acts as the system's core intelligence.
- This setup allows the model to be fine-tuned for speech recognition while preserving the extensive, specialized knowledge already built into the LLM.
This creates a system that minimizes hallucinations while maintaining the contextual understanding that makes medical transcription accurate.
Slam-1 integrates with critical healthcare features like speaker diarization and timestamp prediction. Healthcare developers can use key term prompts to provide up to 1,000 domain-specific terms (pharmaceutical names, procedure codes, anatomical references), and Slam-1 doesn't just watch for those exact matches. It understands their semantic meaning and improves recognition of related terminology throughout the entire transcript.
The data backs it up, too. Slam-1 significantly reduces errors on critical medical terms compared to traditional models. In blind human evaluations, its transcripts are consistently preferred for their accuracy and readability in clinical contexts.
ROI and business impact of medical Voice AI
Medical Voice AI delivers measurable ROI across three key areas: Documentation efficiency: Physicians reduce administrative time from 16 minutes per patient to under 5 minutes. Revenue impact: Improved throughput allows 15-20% more patient appointments daily. Operational savings: Organizations report 40-60% reduction in transcription costs within six months of implementation.
Implementation typically follows a predictable timeline:
- Months 1-2: API integration and pilot program with 5-10 providers
- Months 3-4: Department-wide rollout with workflow optimization
- Months 5-6: Organization-wide deployment and performance measurement
Healthcare organizations consistently report these measurable outcomes: 40-50% reduction in documentation time, 25-35% improvement in physician satisfaction scores, and 15-20% increase in daily patient capacity within six months of full deployment.
The accuracy improvements from advanced Voice AI models also generate substantial operational benefits. Fewer transcription errors mean reduced time spent on corrections, fewer clarification requests between departments, and improved billing accuracy. Healthcare organizations report significant reductions in documentation-related errors when implementing Voice AI solutions that properly handle medical terminology.
Quantify ROI with Voice AI
Discuss HIPAA needs, EHR integration, and a pilot rollout tailored to your workflows. Our team can help model timelines and savings.
Talk to AI expert
Beyond direct time savings, medical Voice AI enables new workflow models that weren't previously feasible. Ambient clinical documentation allows physicians to maintain eye contact with patients during consultations, improving both patient satisfaction scores and clinical outcomes. Real-time documentation reduces the end-of-day charting burden, which the American Medical Association identifies as a key factor contributing to physician burnout.
Industry-specific applications and use cases
Healthcare organizations across specialties are implementing medical Voice AI to solve specific workflow challenges. Success rates vary significantly based on implementation approach and use case selection.
AI Medical Scribes and clinical documentation
Companies like PatientNotes.app and Clinical Notes AI report 70% reduction in physician documentation time through ambient transcription. These platforms capture natural patient-doctor conversations and generate structured clinical notes automatically, allowing physicians to maintain eye contact with patients throughout consultations.
EHR integration and clinical workflows
Healthcare platforms such as T-Pro and MEDrecord integrate Voice AI directly into existing EHR systems, enabling providers to dictate notes, orders, and summaries with 95% accuracy for medical terminology. Organizations typically see 30-40% faster chart completion rates within the first quarter of deployment, a figure supported by one market report which noted a 30% reduction in time spent on administrative tasks at a U.S. hospital network that adopted voice technology.
Telehealth and virtual care platforms
Telehealth providers use Voice AI to automatically document virtual consultations while ensuring compliance with medical record requirements. This dual benefit improves care continuity and reduces post-visit documentation burden for remote care teams.
Specialty-specific implementations
Different medical specialties leverage Voice AI to address their unique documentation challenges. Radiology departments use voice recognition for rapid report generation, while emergency medicine providers rely on real-time transcription to document fast-paced patient encounters. Mental health professionals utilize Voice AI to capture therapy sessions while maintaining patient engagement, and surgical teams employ the technology for operative note dictation.
The leading medical speech recognition solutions
Healthcare organizations are projected to spend $5.58 billion on voice technology by 2035, up from $1.73 billion in 2024. That's an 11.21% compound annual growth rate (CAGR) driven by one simple reality: hospitals can't afford the current broken documentation system.
This growth has created distinct solution categories that each target different aspects of healthcare voice technology:
- Enterprise clinical documentation platforms: Integrate directly with EHR systems. These comprehensive solutions handle everything from voice capture to structured note generation, but they're expensive and often lock healthcare systems into specific workflows.
- Specialized medical dictation tools: Focus on particular environments or specialties. Radiology platforms are great at imaging reports, while pathology systems handle lab documentation. They deliver deep domain expertise but lack flexibility across departments.
- Cloud-based speech services: Provide the API infrastructure that powers healthcare applications. These scalable solutions let developers build custom voice experiences without managing speech recognition infrastructure. They're the engines behind many innovative healthcare tools.
- AI-enhanced medical scribes: Represent the newest category. These platforms generate structured clinical notes from natural conversations. They promise to eliminate documentation time entirely, though accuracy remains non-negotiable for patient safety—a critical point, as a JAMA study found that over 63% of notes generated by speech recognition contained at least one clinically significant error before human revision.
- Mobile documentation solutions: Bring voice technology to smartphones and tablets for point-of-care use. Emergency physicians can dictate notes between patients, and home health workers can document visits on the spot.
AssemblyAI powers applications across all these categories. Healthcare developers choose our Voice AI because it delivers the accuracy of specialized medical models with the flexibility of general-purpose APIs. Whether you're building the next generation of clinical documentation platforms or adding voice features to existing healthcare applications, Slam-1's medical terminology understanding gives you the foundation you need.
Implementation considerations for healthcare developers
Building medical speech recognition solutions isn't like building a consumer app. Get the compliance wrong, and your project dies before it reaches a single patient. Here's what you need to consider:
- Compliance and data security: Any Voice AI handling patient conversations must meet strict healthcare data protection standards, and an industry survey underscores this point, revealing that data privacy and security are among the top three challenges for developers incorporating speech recognition. Look for providers offering end-to-end encryption, SOC 2 compliance, and clear data processing agreements. AssemblyAI provides robust data security, including SOC 2 compliance and the ability to sign a Business Associate Agreement (BAA).
- EHR integration patterns: Most healthcare applications need simple integration with Epic, Cerner, or other electronic health record systems. Plan your API architecture early. Structured data output from speech recognition should map cleanly to your EHR's clinical documentation formats.
- Latency requirements: Real-time clinical documentation demands different performance than batch processing. Emergency departments need sub-second response times, while radiology workflows can tolerate longer processing for higher accuracy.
- Multi-specialty scalability: Healthcare organizations rarely stick to single departments. Your speech recognition solution should handle cardiology terminology as well as pediatrics without requiring separate models or extensive retraining.
Getting these fundamentals right from day one prevents expensive architecture changes later.
Get started with medical Voice AI recognition
Healthcare voice technology spending will reach $5.58 billion by 2035, driven by organizations that can't afford current documentation inefficiencies. Slam-1 delivers 66% reduction in missed medical entity rates compared to traditional models—the breakthrough that makes medical Voice AI practical for any healthcare organization. Early adopters implementing these solutions today gain competitive advantages through improved physician satisfaction, reduced operational costs, and enhanced patient care quality.
The market is moving fast. One market analysis projects the healthcare voice technology market will grow from $5.6 billion in 2024 to $30.5 billion by 2034, and early adopters are already building the applications that will define the next decade of clinical workflows.
See how Slam-1 handles your own medical terminology. Test it in our playground with your own audio samples, or explore our API documentation to start building.
Building an ambient AI scribe?
Get the complete guide to evaluating Voice AI for healthcare—covering clinical accuracy, speech understanding, HIPAA compliance, and the technical capabilities that matter most.
Read the guide
Frequently asked questions about medical voice recognition
How quickly can healthcare organizations expect ROI from medical voice recognition?
Most organizations see measurable benefits within 3-6 months, with documentation time reductions appearing immediately and full ROI typically achieved within 12-18 months.
What is the typical implementation timeline for medical Voice AI solutions?
API-based solutions can be integrated within days for basic functionality, while full EHR integration and staff training typically takes 6-12 weeks.
How does medical voice recognition integrate with existing EHR systems?
Modern Voice AI integrates through standard APIs and HL7/FHIR protocols, with pre-built connectors available for major EHR platforms like Epic and Cerner.
Which medical specialties benefit most from Voice AI implementation?
Radiology, primary care, and emergency medicine show the highest ROI due to high documentation volumes and time-sensitive workflows.
What compliance certifications are required for healthcare voice recognition?
Many organizations require Business Associate Agreements (BAAs) with Voice AI providers.
Title goes here
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.